搜尋引擎最佳化(SEO)已成為提升網站能見度和吸引目標受眾的關鍵策略之一。在這篇文章中,我們將深入探討有效的robots.txt文件建立和管理如何確保網站不僅能被搜尋引擎發現,同時還能吸引和留住訪客。
一、robots.txt的基本概念與運作原理
在深入探討如何有效利用SEO技巧提升網站能見度之前,了解搜尋引擎爬蟲的工作流程以及robots.txt文件的核心角色與功能是不可或缺的一環。首先,我們必須認識到搜尋引擎爬蟲(Web Crawler),也被稱為網路蜘蛛(Spiders)或機器人,是一種自動化的網路程式。它們的主要任務是不斷地瀏覽網際網路,對網站進行掃描和索引,從而幫助搜尋引擎更新其資料庫,提供給用戶更為準確和相關的搜尋結果。在爬蟲執行其任務時,robots.txt文件發揮了關鍵的作用。
位於網站根目錄下的robots.txt是一個純文字文件,它告訴爬蟲哪些部分的網站是可以被抓取的,哪些是不允許的。這能夠幫助網站擁有者控制爬蟲抓取網站的哪些資料,從而避免重要資源的浪費在不必要的頁面上,或是防止某些敏感資訊被索引。透過有效配置robots.txt文件,可以在不影響用戶體驗的前提下,優化網站的搜尋引擎排名。
二、robots.txt文件的相關指令
文件的結構包括幾種主要指令:
-
User-agent指令:可以針對特定或所有搜尋引擎爬蟲定義規則,搭配*的使用(User-agent: *)是其中一個指令,它告訴所有的網路爬蟲,無論是誰,都要遵守以下的規則。
-
Disallow指令:明確指出哪些目錄或頁面是禁止爬蟲檢索的,以下為例:
Disallow: /private/:將阻止爬蟲抓取任何位於/private/目錄下的內容。
-
Allow指令:可以指定即便在Disallow規則下,仍然允許檢索的特定內容。
-
Crawl-delay指令: 非必要項目,用於指定爬蟲檢索網站的延遲時間(以秒為單位)。
-
Sitemap指令: 非必要項目,用於指定網站的 XML 網站地圖檔案的位置。
更多關於Sitemap的相關資訊 >>Sitemap是什麼?網站地圖DIY教學與SEO應用
三、robots.txt的常見規則範例
在深入了解robots.txt文件如何幫助提升網站SEO表現之前,讓我們先從三個主要應用場景來探討其靈活性與重要性。
-
對於那些希望完全阻止搜尋引擎爬蟲抓取其網站的網站擁有者,可以通過添加如下簡單的規則到robots.txt文件來達成這一目的:
User-agent: *
Disallow: /
此規則對所有搜尋引擎爬蟲(User-agent: *表示這條規則適用於所有爬蟲)發出指令,不允許它們抓取網站上的任何頁面(Disallow: /表示根目錄及以下的所有內容都不應被抓取)。
-
如果網站擁有者僅希望特定的爬蟲能夠抓取其網站,可以通過如下方式指定:
User-agent: Googlebot-news
Disallow:
User-agent: *
Disallow: /
在這個例子中,我們首先允許Googlebot-news(Google新聞的爬蟲)抓取網站的所有內容(第一條規則中的Disallow後未指定路徑,表示沒有禁止抓取的內容),然後通過第二條規則禁止所有其他爬蟲抓取網站。
-
當網站擁有者想要阻止特定爬蟲抓取網站上的某些特定目錄或頁面時,可以設置如下規則:
User-agent: Baiduspider
Disallow: /private-directory/
這條規則明確禁止名為Baiduspider的爬蟲抓取/private-directory/目錄下的所有內容,從而保護網站上的敏感或私人內容不被不受歡迎的爬蟲抓取。
通過這些範例,我們可以看出robots.txt文件為網站擁有者提供了一種靈活而強大的工具,以精確控制搜尋引擎爬蟲對其網站的抓取。這不僅有助於保護網站的私密內容,還能確保網站的關鍵資訊能夠被適當索引,進而提升網站在搜尋引擎中的能見度。
四、如何建立與測試robots.txt檔案
使用文字編輯器建立
建立與測試robots.txt文件的過程中,首先需要使用文字編輯器創建這個文件。選擇偏好的文字編輯器,如Notepad或Sublime Text,然後根據網站的需求撰寫適當的指令,包括User-agent、Disallow、Allow等。完成後,將文件儲存為robots.txt並上傳至網站根目錄。當搜尋引擎爬蟲抓取網站時,將會首先檢查這個文件並按照其指令進行內容爬取。在設定robots.txt文件時,也必須謹慎以避免誤封鎖對SEO友好的重要內容。
利用robots.txt測試工具檢查
在robots.txt文件創建完畢後,進行測試以確保其能正確引導搜尋引擎爬蟲是關鍵一步。你可以使用Google Search Console檢查 robots.txt 檔案是否存在,也可以檢查文件並修正任何潛在的問題。點擊「開啟robot.txt報表」即可開始使用:
圖片來源:截自Google Search Console說明中心
-
已擷取:若上次嘗試檢索時有成功傳回 robots.txt 檔案,狀態會顯示「已擷取」,而剖析檔案時發現的問題全都會列在「問題數」欄中。
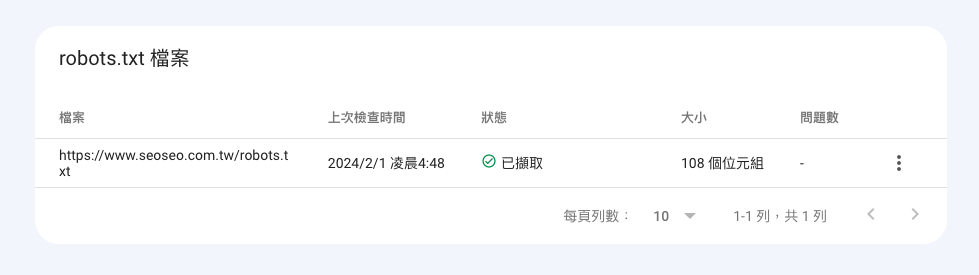 圖片來源:截自Google Search Console
圖片來源:截自Google Search Console
如要修正剖析問題,則可以利用第三方測試工具如robots.txt Validator and Testing Tool | TechnicalSEO.com。這確保了文件在正式運作前不會阻擋到重要內容的索引。
-
未擷取:若上次嘗試檢索時robots.txt 檔案不存在,狀態會顯示「未擷取」,可以嘗試檢查網址看看是否有任何問題。
其他相關使用說明可參考:robots.txt 報表 - Search Console說明
五、robots.txt的SEO最佳作法
在探討robots.txt對SEO的影響時,有幾項值得注意的事:
-
確保不會不小心阻擋到重要頁面的爬取:robots.txt文件使網站管理者能夠指示搜尋引擎哪些頁面或文件應被抓取,哪些則不應該,錯誤地設定禁止爬取重要頁面可能會導致這些頁面無法出現在搜尋結果中,進而影響網站的可見度和流量。
-
了解noindex meta標籤和robots.txt之間的區別:noindex meta標籤位於HTML頁面內部,用於告知搜尋引擎不要將該頁面納入索引,而robots.txt則控制爬蟲對網站的抓取。簡而言之,noindex是防止頁面被索引(index),robots.txt是防止頁面被爬取(crawl)。
更多關於noindex meta標籤的相關資訊 >>精通SEO:如何運用Robots Meta標籤與X-Robots-Tag提升網站排名
-
定期更新和提交robots.txt文件:隨著網站內容的更新和擴充,可能需要調整robots.txt文件,以確保新的或更新的內容能被搜尋引擎正確爬取和索引。當robots.txt有重要更改時,應通過Google Search Console等工具提交更新,以加速搜尋引擎對這些變更的識別。透過定期檢查和更新robots.txt文件,可以確保SEO策略與網站發展保持一致,從而有效提升網站在搜尋引擎中的表現,增加網站的可見度和訪客流量。
還想了解更多各類數位行銷資訊的話,歡迎訂閱電子報、加入奇寶Line好友,第一時間接收最新資訊!後續我們台北移動學苑還會陸續舉辦各類型的行銷課程,也歡迎有興趣的行銷人可以加入我們臉書粉絲團,在粉絲專頁上與我們討論喔!
Facebook粉絲專頁:
歡迎轉載KPN奇寶部落格相關文章,在轉載前請先詳閱著作權聲明及轉載原則
還想了解更多各類數位行銷資訊的話,歡迎訂閱電子報、加入奇寶 Line 好友,第一時間接收最新資訊!
歡迎轉載 KPN 奇寶部落格相關文章,在轉載前請先詳閱著作權聲明及轉載原則。