就在 2025 年 10 月,一份剛出爐的學術研究 "Characterizing Web Search in The Age of Generative AI" (arXiv:2510.11560v1),為这个新戰場揭示了革命性的規則。這份研究的目的非常明確:首次系統性地量化分析「AI 搜尋」與「傳統搜尋」在引用來源、內容策略和面對不同用戶意圖時,究竟存在哪些根本性的差異。而它的核心結論,為所有行銷人劃下了全新的戰場規則。
快速導讀陪你一起讀文章
- 發現一:「功能分化」— AIO 成為資訊研究員,SERP 堅守商業導購員
- 發現二:「越級抓取」— AIO 無視 Top 10 排名,只看主題權威
- 發現三:「知識依賴差異」— 內部知識 vs. 外部檢索
- 發現四:「結果不穩定」— AIO 穩定性遠低於傳統搜尋
- 發現五:「AIO 的局限」— 刻意避開高風險、高商業性與即時性內容
第一部分:本研究的五大核心發現
研究人員透過嚴謹的測試(詳見附錄),得出了五大革命性發現:
發現一:「功能分化」— AIO 成為資訊研究員,SERP 堅守商業導購員
研究證實,AI 搜尋會將多來源資訊整合為一段「敘事式」文字,專注在回答開放性、複雜的「資訊型」問題。然而,傳統 SERP(10 條獨立連結)在處理具有明確「商業意圖」或「交易意圖」的查詢時,依然保持著穩固的主導地位。
發現二:「越級抓取」— AIO 無視 Top 10 排名,只看主題權威
這可能是對 SEO 業者最衝擊的發現。過去我們追求 Top 10 排名,但研究數據顯示:
- AIO 引用的來源中,高達 53% 不在傳統 SERP 的 Top 10。
- 甚至有 27% 的引用來源,連 Top 100 都排不進去。
這意味著 AIO 使用一套全新的標準來判斷「誰是專家」,它會「越級」抓取它認為在特定「主題」上最權威的內容,而不再迷信「頁面排名」。
發現三:「知識依賴差異」— 內部知識 vs. 外部檢索
研究發現,不同的 AI 搜尋引擎對「即時網路資訊」的依賴程度差異極大。
- 重度依賴內部知識: 某些模型(如 GPT-Tool)傾向用自己預先訓練好的內部知識回答,很少檢索網頁。
- 重度依賴外部檢索: 另一些(如 AIO、Gemini、GPT-Search)則會大量檢索外部網頁,以確保資訊的即時性。
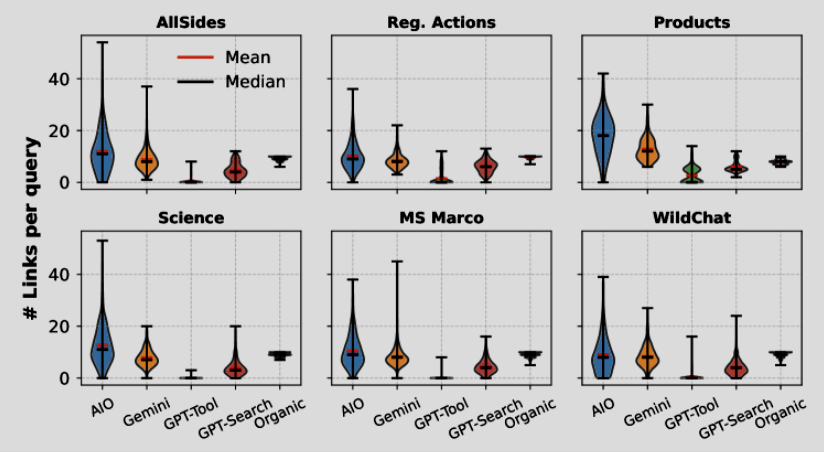
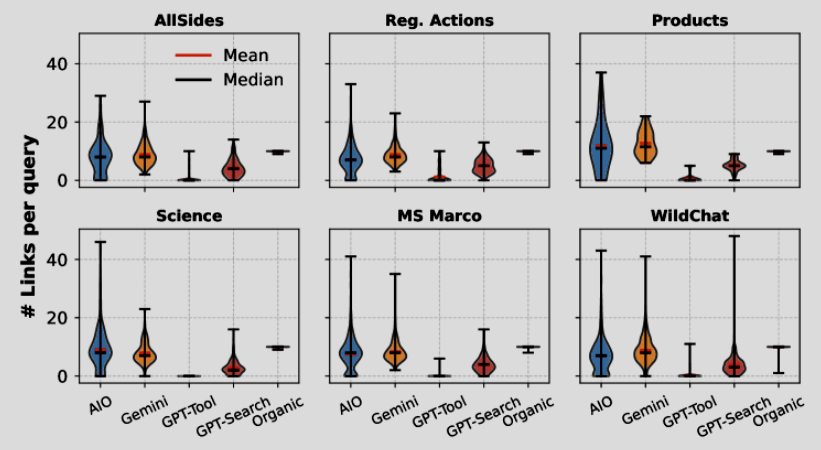
發現四:「結果不穩定」— AIO 穩定性遠低於傳統搜尋
研究人員在不同時間重複測試相同的查詢,發現了驚人的差異:
- 傳統搜尋 (Organic): 來源穩定度最高,約 45% 的連結在不同時間點依然相同。
- AIO (Google AI Overview): 波動性極高,來源連結僅有約 18% 相同。
這意味著 AIO 的內容是高度動態的,可能每天都在變化。
發現五:「AIO 的局限」— 刻意避開高風險、高商業性與即時性內容
研究也發現,AIO 並非萬能。在特定情況下,它的觸發率極低或表現不佳:
- 即時趨勢: 在「Trending Queries」(熱門趨勢)的測試中,AIO 觸發率僅 3%。只有「具檢索能力」的模型能處理即時資訊。
- 模糊查詢: 對於意圖不明確的字詞(例如同名人物),AIO 涵蓋度不如傳統 SERP。
- 高風險議題: AIO 會刻意迴避可能引發爭議的敏感內容。
第二部分:KPN 奇寶的在地洞察:趨勢的雙重驗證
這份 10 月的學術研究固然震撼,但更令我們振奮的是—— KPN 奇寶早在 2025 年 8 月,針對台灣市場(醫美、旅遊、產險業)的在地觀察報告中,就已得出了「幾乎一致」的結論。
這證實了我們在台灣看到的趨勢並非特例,而是一個全球性的典範轉移。
- KPN 觀察 (一):完美呼應「功能分化」(呼應發現一 & 五) KPN 在 8 月的報告就指出 AIO 與 SERP 的「一國兩制」。例如:
- 「隆乳材質」: AIO 提供客觀的材質比較(資訊型);SERP 則充滿各家診所服務(交易型)。
- 「歐洲蜜月」: AIO 提供規劃技巧(資訊型);SERP 則顯示旅行社行程(交易型)。
- 結論: KPN 的在地數據,完美驗證了這份研究的「功能分化」發現。
- KPN 觀察 (二):率先發現 AIO 避開「黃金關鍵字」(呼應發現五) KPN 在 8 月就發現 AIO 會「刻意不碰」某些高價值關鍵字,這呼應了該研究發現的 AIO 局限性:
- 地區型 / 商業意圖強: AIO 迴避「台北醫美」、「奧捷旅行社」。
- 泛稱、範圍過廣: AIO 迴避「汽車保険」、「歐洲旅遊」。
- 敏感 / 高風險議題: AIO 迴避「隆乳手術」、「平胸手術」。
第三部分:行銷人的新行動方案 (基於雙重驗證的策略)
既然 KPN 的在地數據與這篇研究一致,行銷人不能再忽視。這不再是猜測,而是已經被雙重驗證的事實。 我們必須立刻行動,調整策略以爭取 AI 的曝光機會:
行動一:審計你的關鍵字意圖 (AIO vs. SERP)
你必須重新檢視你的所有關鍵字,並將它們明確分類:
- AIO 潛力字(資訊型): 標記出所有「是什麼」、「為什麼」、「如何做」、「...比較」的關鍵字。
- SERP 必爭字(商業型): 標記出所有「購買」、「價格」、「推薦」、「...廠商」、「...地區」的關鍵字。
行動二:打造「雙軌內容」資產 (TOFU vs. BOFU)
不要再試圖用一篇內容同時滿足兩種意圖。
- AIO 導向: 針對「AIO 潛力字」,建立你的「權威指南」或「知識庫」。內容必須客觀、深入、結構清晰,目標是成為 AI 的答案來源。
- SERP 導向: 針對「SERP 必爭字」,強化你的「登陸頁(Landing Page)」。內容精準、CTA 明確,全力爭取轉換。
行動三:建立「主題權威」(應對發現二:越級抓取)
這是應對「越級抓取」發現的最重要策略。
- 集中火力,讓你網站在特定「核心主題」上(例如「隆乳材質」、「歐洲蜜月規劃」)成為無可爭議的權威。你那些排名不佳但品質極高的長尾內容,現在有了被 AIO 直接引用的機會。
第四部分:結論
KPN 奇寶在 8 月份的台灣市場數據中已經捕捉到了這個訊號。而 10 月份剛發布的國際研究,則從學術上精確地證實了這一點。
這份研究最重要的啟示是: 傳統的 SEO 評估指標(如 nDCG、頁面排名)已不足以應對 AIO 時代。我們需要建立新的評估方法,轉而關注「資源多樣性」、「概念涵蓋度」與「資訊真實性」。
請記住,根據 KPN 的數據,在台灣市場,「自然流量」(Organic)依然是各大產業最主要的流量來源。SEO 這場遊戲沒有結束,只是規則升級了。
對於希望深入了解本研究如何進行的讀者,以下是對其研究方法的深度解析。附錄:研究方法深度拆解 (選讀)
【研究方法深度解析 (一):為何研究要用「六種不同資料集」?】
六種資料集,就是代表六種不同的「用戶意圖」
您可以把這六種資料集想像成六種不同的「考卷」,研究人員拿著這六張考卷,分別去考 AIO、Gemini、GPT-Search、GPT-Tool 和 Organic Search 這五位考生。
- 考卷 A (MS Marco / WildChat - 一般真實查詢):
- 目的: 測試模型應對「一般人」的真實、隨機的日常問題時的表現。
- 考卷 B (Products - 高商業意圖):
- 目的: 專門測試模型在「購物、比價」等高商業意圖查詢上的策略。
- 考卷 C (AllSides - 政治偏向性):
- 目的: 測試模型在處理「敏感、具爭議性」的政治議題時,是否會迴避或展現偏見。
- 考卷 D (Science Queries - 專業領域):
- 目的: 測試模型在「專業、深入」的知識型問題上的表現。
- 考卷 E (Regulatory Actions / Trending Queries - 即時性):
- 目的: 這是最關鍵的測試之一。專門用來測試模型對「剛發生的新資訊」(例如最新的行政命令或 Google Trends 熱搜)的掌握能力。
結論:研究的完整流程
研究人員的完整流程是:
-
拿起「考卷 A (MS Marco)」裡的所有問題。
-
用這些同樣的問題去問 AIO、Gemini、GPT... 等五位考生。
-
記錄下他們的答案和引用來源。
-
接著,拿起「考卷 B (Products)」裡的所有問題。
-
再次用這些同樣的問題去問那五位考生。
-
...依此類推,直到六套考卷全部測完。
正是因為他們使用了這六種不同意圖的資料集,並且在每一種資料集內都用了同樣的問句去測試所有模型,他們才能如此有信心地得出普遍性的結論。
【研究方法深度解析 (二):AI 如何分析「概念」而非「關鍵字」? (LLooM 框架)】
1. 什麼是「LLooM 框架」? LLooM 是一個縮寫,它是一種學術上用來做「主題推論 (Topic Inference)」的方法名稱。
簡單來說,它不是一個現成的軟體,而是這群研究人員使用的一套「用 AI 來分析 AI」的方法論。 它的全名是 "Large Language Model-powered concept induction framework" (由大型語言模型驅動的概念歸納框架)。
2. 什麼是分析「概念 (Concept)」? 這點非常重要。傳統的 SEO 內容分析是看「關鍵字 (Keyword)」有沒有出現。但 AI 時代,我們必須分析更高維度的「概念 (Concept)」。
- 關鍵字 (Keyword): 「不平等 數學」、「不平等 社會」
- 概念 (Concept): 「數學上的不平等」(Mathematical Concepts)、「社會性的不平等」(Inequality Expressions)
您可以看到,「概念」是一個更高層次、更接近「用戶意圖」的想法。這份研究的精華就在於,它不是在計算 AIO 和 SERP 出現了多少相同的「關鍵字」,而是在計算它們涵蓋了多少相同的「概念」。
3. LLooM 框架是如何運作的?(兩階段) 這套方法精巧地運用 AI 做了兩件事:
- 階段一:歸納 (Induction) - 「這堆答案裡總共有哪些概念?」 研究人員針對一個查詢 (例如研究中的 Figure 2:「什麼是不平等的例子?」)。 他們會把 AIO、Gemini、GPT-Search 和 Organic SERP (前 10 名) 的所有回答文本,全部丟給 LLooM (也就是一個強大的 AI, 如 GPT-4o)。 他們對 AI 下達指令 (Prompt),要求 AI 閱讀這所有資料後,歸納出一張「概念總表 (Master List)」。 所以 AI 會吐出一張清單,就像 Figure 2 的 X 軸:「數學概念」、「法規表述」、「符號表示」、「社會不均」...等等。
- 階段二:標註 (Classification) - 「AIO 涵蓋了其中幾個概念?」 現在有了一張「概念總表」。 研究人員再回過頭來,單獨拿出一個回答 (例如「AIO 的回答」)。 他們再次對 AI 下指令:「請判斷這份 AIO 的回答,是否涵與了『數學概念』?(是/否)」、「是否涵與了『法規表述』?(是/否)」... AI 會逐一標註。 他們對 Gemini、GPT-Search、Organic SERP 也都重複做一次這個標註動作。
最終結果: 他們得到了一張「概念覆蓋表」(這就是您看到的 Figure 2),這張表清晰地顯示了,面對同一個問題,AIO 選擇回答了哪些概念、Organic SERP 選擇了哪些,而 Gemini 又選擇了哪些。
所以,「AI (LLooM 框架) 來分析『概念』」這句話,翻譯成白話就是:
「研究人員使用一套『AI 分析法』,先從所有搜尋結果中歸納出『所有可能的答案面向』,然後再回頭去標註 AIO、SERP 各自回答了其中的哪幾個面向,以此來量化它們的內容策略差異。」
這就是為什麼我們能在 Figure 2 中看到,AIO 和 Organic SERP 在回答同一個問題時,其「內容的廣度」和「策略的偏好」是截然不同的。這也是我們在重現研究時,最高階也最有價值的一個分析步驟。
資料來源:Characterizing Web Search in The Age of Generative AI
還想了解更多各類數位行銷資訊的話,歡迎訂閱電子報、加入奇寶Line好友,第一時間接收最新資訊!後續我們台北移動學苑還會陸續舉辦各類型的行銷課程,也歡迎有興趣的行銷人可以加入我們臉書粉絲團,在粉絲專頁上與我們討論喔!
Facebook粉絲專頁:
歡迎轉載KPN奇寶部落格相關文章,在轉載前請先詳閱著作權聲明及轉載原則
還想了解更多各類數位行銷資訊的話,歡迎訂閱電子報、加入奇寶 Line 好友,第一時間接收最新資訊!
歡迎轉載 KPN 奇寶部落格相關文章,在轉載前請先詳閱著作權聲明及轉載原則。