解析 Google 2026年最新指南,從技術與演算法機制看懂為什麼你不該把預算花在「AI 偏方」上。近期市場上充斥著 AEO (Answer Engine Optimization) 與 GEO (Generative Engine Optimization) 的焦慮。許多聲音告訴我們,必須要為了 AI 寫一套全新的語法、切碎內容,甚至建立 AI 專用的檔案。然而,Google 官方在《針對 Google 搜尋上的生成式 AI 功能最佳化您的網站》中明確表態:不需要針對 AI 進行特殊格式處理。 本文將為各位專業工作者拆解這背後的技術機制,讓你知其然,更知其所以然。
一、觀念一:捨棄建立專屬的 llms.txt 檔案
名詞基礎介紹:llms.txt 檔案
這是在 AI 開發圈近期流行的一種做法,提喚在網站根目錄放一個純文字或 Markdown 格式的 llms.txt 檔案。其目的是將網站內容剝除所有 HTML 標籤、導覽列與側邊欄,只留下最純粹的文字,試圖讓大語言模型 (LLMs) 更容易「閱讀」與抓取。
機制拆解:為什麼不需要另外製作?
因為 Google 搜尋的 AI 功能(如 AI Overviews)並不是直接派出一個 LLM 去爬你的網站。AI 功能是建立在 Google 原本強大的網路轉譯服務 (WRS, Web Rendering Service) 與索引庫之上的。Googlebot 早就具備極強的 DOM 解析能力,能自動剝除導覽列 (Boilerplate) 並萃取主要內容 (Main Content)。提供llms.txt是多此一舉,且 Google 系統根本不會特別去讀取它來作為排名的依據。
架構圖說:Google 爬取與 AI 產出的真實流程
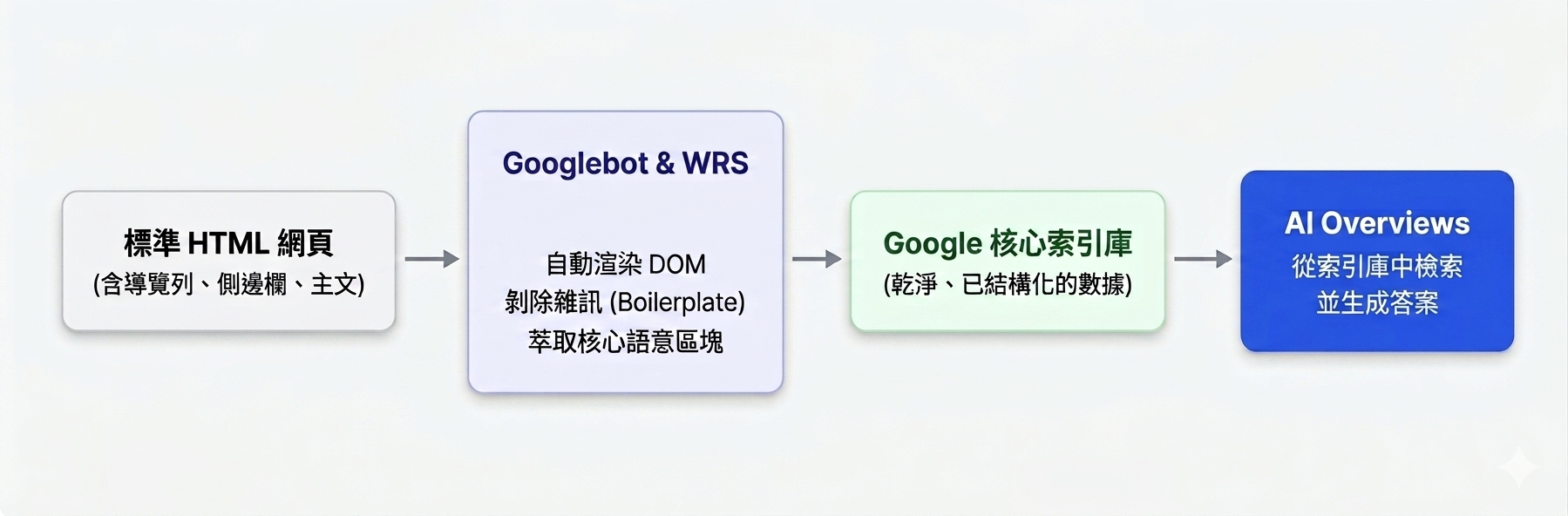
圖表 1:AI 生成結果是基於 Google 原有的索引庫,而非直接讀取純文字檔。Google 的渲染技術已完全能處理複雜 HTML。
實務優化建議:與其花時間維護一個容易與 HTML 版本內容不同步的 txt 檔案,不如確保你的網站 HTML 架構使用了語意化標籤(Semantic HTML,如,),這對 WRS 解析幫助最大。
二、觀念二:無需刻意進行「內容分塊」(Content Chunking)
名詞基礎介紹:內容分塊
在早期 RAG(檢索增強生成)技術中,為了避免受限於 AI 較小的上下文視窗 (Context Window),工程師會將長篇文章硬性切割成 300-500 字的獨立小區塊(Chunks)。有 SEO 觀點認為,網站文章也應該刻意寫成許多互不相連的小段落,每個段落獨立回答一個小問題,以迎合 AI 抓取。
機制拆解:為什麼不需要另外製作?
現代大型語言模型(如 Google Gemini)具備高達數百萬 Token 的超大上下文窗口,能夠一次性理解整本巨作的語境。如果刻意把長篇專業文章切碎成互不連貫的小區塊,反而會破壞文章的全域語意連貫性 (Global Semantic Coherence)與實體關聯。Google 的系統更青睞能夠全面涵蓋主題、具備深度與邏輯推進的「長篇知識脈絡」,而非破碎的 Q&A 集合。
架構圖說:語意關聯性對比
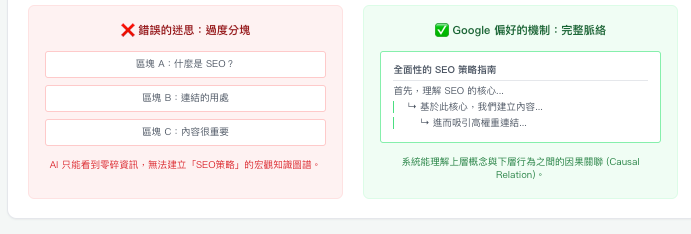
實務優化建議:請正常撰寫長篇深度文章,善用標籤建立清晰的大綱層次 (Document Outline) 即可。人類讀起來覺得邏輯順暢的文章,現在的 AI 就能理解得很好。
三、觀念三:停止迎合「機器語氣」與堆疊同義詞
名詞基礎介紹:機器語氣 / 語義堆疊
過去的 SEO 為了讓演算法看懂,常會使用非常生硬的句子,把「買車」、「購車」、「購買汽車」等同義詞全部硬塞在同一個段落裡。而在 AI 時代,有些人誤以為 AI 像傳統的關鍵字比對系統一樣「笨」,因此刻意用極度公式化、條列式的無聊語氣來寫作,試圖餵養 AI。
機制拆解:為什麼不需要另外製作?
Google 的核心搜尋引擎早已全面導入NLP(自然語言處理)與向量嵌入 (Vector Embeddings)技術。在向量空間模型中,「買」跟「購」在多維空間的距離極近,系統完全知道它們是同一件事。迎合機器的語氣不僅多餘,反而會降低文章的獨特性(Non-commodity)。Google AI 尋找的是帶有「真實人類經驗」與「觀點」的內容,公式化的廢話會被過濾機制視為低價值內容。
架構圖說:向量空間 (Vector Space) 概念圖

▲ 圖表 3:在 AI 的向量空間中,同義詞會自動群聚(Cluster),不需在文章中堆疊關鍵字,寫得像正常人說話即可。
實務優化建議:專注於展現E-E-A-T (經驗、專業、權威、信任)。分享您的第一手實務經驗、客戶案例、甚至是失敗的教訓。這些帶有強烈個人/品牌觀點的內容,才是 AI 模型無法自行無中生有、必須引用您的文章的高價值資產。
四、觀念四:別被「專屬 AI 結構化資料」的話術欺騙
名詞基礎介紹:AI 專屬 Schema Markup
坊間有些服務商聲稱,為了讓 AI 認識你的網站,必須埋設一套「全新、專為 AI 設計」的 JSON-LD 結構化資料。宣稱傳統的 Schema.org 標籤對 AI 無效。
機制拆解:為什麼不需要另外製作?
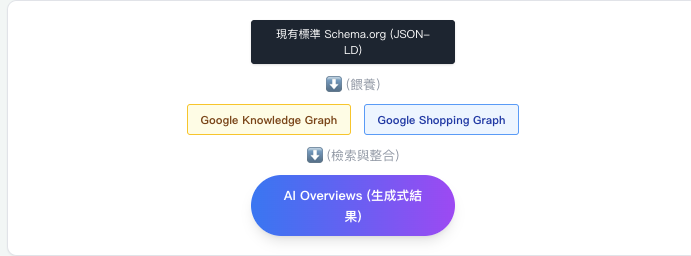
Google 搜尋 AI 的知識底底層,有很大一部分是依賴 Google 累積多年的知識圖譜 (Knowledge Graph)與購物圖譜 (Shopping Graph)。而這些圖譜的資料來源,正是我們原本就在做的標準Schema.org結構化資料(如:Article,Product,LocalBusiness,FAQPage)。Google 官方明確指出,沿用現有標準的技術 SEO 即可,根本不存在所謂「Google AI 專屬的隱藏版 Schema 格式」。
架構圖說:資料流向圖 (Data Flow)
實務優化建議:把基礎功做扎實。如果是電商,請確保 Product Schema 中的價格、庫存、評價資料正確,並綁定 Google Merchant Center;如果是實體店,好好維護 Google 商家檔案 (Business Profile)。這才是影響 AI 引用實體資料的關鍵核心。
五、總結:致行銷人的最終建議
AEO 與 GEO 的崛起,反映了市場對於未知技術的焦慮。但從工程與演算法的底層機制來看,Google 已經明確表示:生成式 AI 只是另一種呈現搜尋結果的方式,其資料擷取的核心基礎依然是傳統的 SEO。
- 停止尋找技術捷徑(如llms.txt、過度分塊)。
- 停止撰寫機器才會看的公式化廢話。
- 全力投入:產出帶有獨特觀點、真實經驗的深度內容,並維持完美的技術 SEO 體質。
記住,當所有競爭對手都在用 AI 批量生成「商品化內容 (Commodity content)」時,您願意投入時間撰寫的「真實案例與獨特觀點」,就會是 Google AI 系統眼中最閃亮的稀缺資源。
還想了解更多各類數位行銷資訊的話,歡迎訂閱電子報、加入奇寶Line好友,第一時間接收最新資訊!後續我們台北移動學苑還會陸續舉辦各類型的行銷課程,也歡迎有興趣的行銷人可以加入我們臉書粉絲團,在粉絲專頁上與我們討論喔!
Facebook粉絲專頁:
歡迎轉載KPN奇寶部落格相關文章,在轉載前請先詳閱著作權聲明及轉載原則
還想了解更多各類數位行銷資訊的話,歡迎訂閱電子報、加入奇寶 Line 好友,第一時間接收最新資訊!
歡迎轉載 KPN 奇寶部落格相關文章,在轉載前請先詳閱著作權聲明及轉載原則。